27장 배열
JS에 배열이라는 타입은 존재하지 않는다. 배열은 객체 타입이다.
배열이 생성자 함수는 Array 이며 배열의 프로토타입 객체는 Array.prototype이다.
배열은 객체지만 일반 객체와 차이점이 있음.
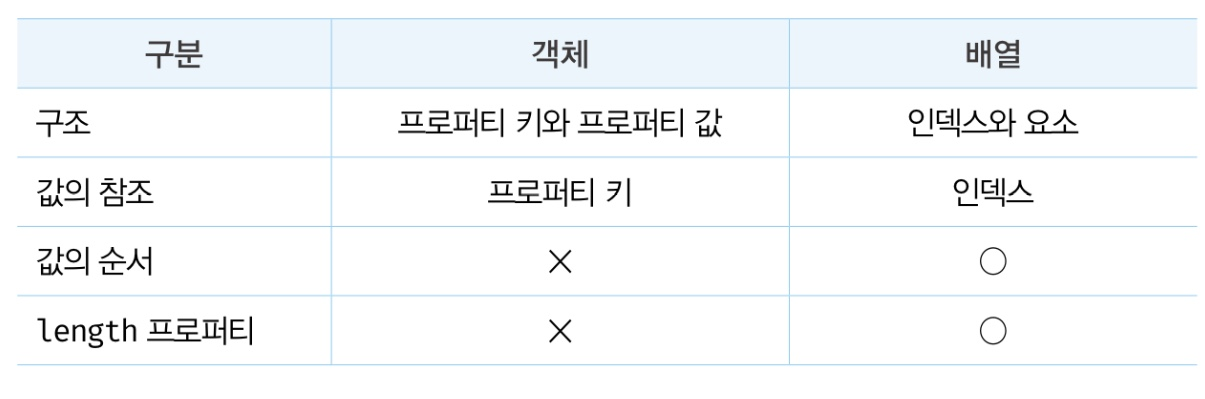
가장 큰 차이는 값의 순서 와 length 프로퍼티
const arr = [1, 2, 3];
// 반복문으로 자료 구조를 순서대로 순회하기 위해서는 자료 구조의 요소에 순서대로
// 접근할 수 있어야 하며 자료 구조의 길이를 알 수 있어야 한다.
for (let i = 0; i < arr.length; i++) {
console.log(arr[i]); // 1 2 3
}
자바스크립트 배열은 배열이 아니다
자료구조에서 배열은 동일한 크기의 메모리 공간이 빈큼없이 연속적으로 나열된 자료구조를 말한다.
서로 연속적으로 인접해 있는 이러한 배열을 밀집배열이라고 한다.
빈틈없이 연속적으로 이어져있어서 인덱스를 통해 단 한번의 연산으로 요소에 접근가능하기에 O(1) 의 시간 복잡도를 가진다.
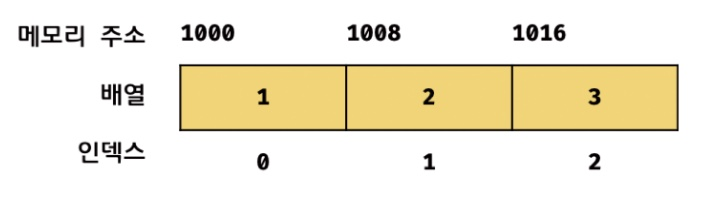
특정한 요소를 검색할 때는 시간복잡도 O(n)을 가진다.
배열을 삽입하거나 삭제할 대는 배열의 요소들을 전체적으로 이동시켜야하는 단점도 있다.
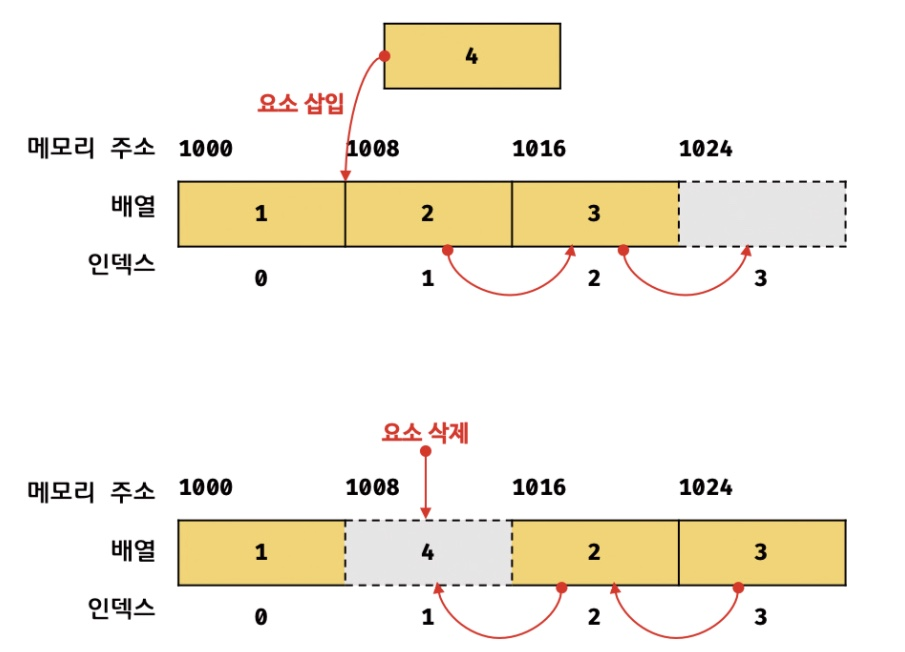
자바스크립트에서 배열은 일반적인 의미의 배열과 다르다.
요소를 위한 각각의 동일한 크기의 메모리 공간을 갖지 않아도 되고, 연속적으로 이어져 있지 않을 수도 있다.
연속적이지 않은 배열을 희소배열이라 한다.
자바스크립트의 배열은 일반적인 배열의 동작을 흉내 낸 특수한 객체이다.
// "16.2. 프로퍼티 어트리뷰트와 프로퍼티 디스크립터 객체" 참고
console.log(Object.getOwnPropertyDescriptors([1, 2, 3]));
/*
{
'0': {value: 1, writable: true, enumerable: true, configurable: true}
'1': {value: 2, writable: true, enumerable: true, configurable: true}
'2': {value: 3, writable: true, enumerable: true, configurable: true}
length: {value: 3, writable: true, enumerable: false, configurable: false}
}
*/
인덱스를 나타내는 문자열을 프로퍼티 key로 가지고 length 프로퍼티를 갖는 특수한 객체.
즉, JS 배열은 요소 접근은 느리지만 요소 검색, 삽입 삭제는 일반 배열보다 빠르다.
length 프로퍼티와 희소배열
희소 배열은 length와 배열요소의 개수가 일치하지 않는다.
// 희소 배열
const sparse = [, 2, , 4];
// 희소 배열의 length 프로퍼티 값은 요소의 개수와 일치하지 않는다.
console.log(sparse.length); // 4
console.log(sparse); // [empty, 2, empty, 4]
// 배열 sparse에는 인덱스가 0, 2인 요소가 존재하지 않는다.
console.log(Object.getOwnPropertyDescriptors(sparse));
/*
{
'1': { value: 2, writable: true, enumerable: true, configurable: true },
'3': { value: 4, writable: true, enumerable: true, configurable: true },
length: { value: 4, writable: true, enumerable: false, configurable: false }
}
*/
배열 생성
Array 생성자 함수
- 전달된 인수가 1개이고 숫자인 경우 : length 프로퍼티 값이 인수인 희소배열 생성
- 인수가 2개이상이거나 숫자가 아닌경우 : 인수를 요소로 갖는 배열 생성’
Array.of
전달된 인수를 요소로 갖는 배열 생성
1개여도 인수가 된다는 차이
// 전달된 인수가 1개이고 숫자이더라도 인수를 요소로 갖는 배열을 생성한다.
Array.of(1); // -> [1]
Array.of(1, 2, 3); // -> [1, 2, 3]
Array.of('string'); // -> ['string']
Array.from
유사 배열 객체 또는 이터러블 객체를 인수로 전달받아 배열로 변환하여 반환
// 유사 배열 객체를 변환하여 배열을 생성한다.
Array.from({ length: 2, 0: 'a', 1: 'b' }); // -> ['a', 'b']
// 이터러블을 변환하여 배열을 생성한다. 문자열은 이터러블이다.
Array.from('Hello'); // -> ['H', 'e', 'l', 'l', 'o']
배열 요소의 참조
존재 하지 않는 요소에 접근하면 undefined 반환
배열 요소의 추가와 갱신
객체에 프로퍼티 동적으로 추가하듯이 배열에도 요소 동적으로 추가할 수 있음.
인덱스는 정수나 정수 형태의 문자열 사용해야함.
요소 추가하면 length 자동으로 갱신됨.
배열 요소의 삭제
delete 연산자로 배열 요소 삭제
const arr = [1, 2, 3];
// 배열 요소의 삭제
delete arr[1];
console.log(arr); // [1, empty, 3]
// length 프로퍼티에 영향을 주지 않는다. 즉, 희소 배열이 된다.
console.log(arr.length); // 3
delete 연산자는 객체의 프로퍼티를 삭제하기 대문에 희소배열이 되며, length 프로퍼티 값은 변하지 않는다
⇒ 희소배열 만들지 않으면서 특정 요소 삭제하려면 Array.prototype.splice 메서드 사용해라
const arr = [1, 2, 3];
// Array.prototype.splice(삭제를 시작할 인덱스, 삭제할 요소 수)
// arr[1]부터 1개의 요소를 제거
arr.splice(1, 1);
console.log(arr); // [1, 3]
// length 프로퍼티가 자동 갱신된다.
console.log(arr.length); // 2
배열 메서드
원본 배열을 변경하는 메서드와, 변경하지않고 새로운 배열을 생성해서 반환하는 메서드가 있으므로 주의해서 사용.
Array.isArray
Array.isArray 는 생성자 함수의 정적 메서드이다.
전달된 인수가 배열이면 true, 아니면 flase 반환
// true
Array.isArray([]);
Array.isArray([1, 2]);
Array.isArray(new Array());
// false
Array.isArray();
Array.isArray({});
Array.isArray(null);
Array.isArray(undefined);
Array.isArray(1);
Array.isArray('Array');
Array.isArray(true);
Array.isArray(false);
Array.isArray({ 0: 1, length: 1 })
Array.prototype.indexOf
원본 배열에서 인수로 전달된 요소를 검색해서 인덱스를 반환.
- 여러개여도 첫번째 요소의 인덱스만 반환
- 존재하지 않으면 -1 반환
const arr = [1, 2, 2, 3];
// 배열 arr에서 요소 2를 검색하여 첫 번째로 검색된 요소의 인덱스를 반환한다.
arr.indexOf(2); // -> 1
// 배열 arr에 요소 4가 없으므로 -1을 반환한다.
arr.indexOf(4); // -> -1
// 두 번째 인수는 검색을 시작할 인덱스다. 두 번째 인수를 생략하면 처음부터 검색한다.
arr.indexOf(2, 2); // -> 2
요소가 존재하는지만 보려면 Array.prototype.includes 가 가독성 좋다
const foods = ['apple', 'banana'];
// foods 배열에 'orange' 요소가 존재하는지 확인한다.
if (!foods.includes('orange')) {
// foods 배열에 'orange' 요소가 존재하지 않으면 'orange' 요소를 추가한다.
foods.push('orange');
}
console.log(foods); // ["apple", "banana", "orange"]
Array.prototype.push
인수로 전달 받은 모든 값을 원본 배열의 마지막 요소로 추가하고 lengh 프로퍼티 값을 반환
→ 원본 배열을 직접 변경
const arr = [1, 2];
// 인수로 전달받은 모든 값을 원본 배열 arr의 마지막 요소로 추가하고 변경된 length 값을 반환한다.
let result = arr.push(3, 4);
console.log(result); // 4
// push 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [1, 2, 3, 4]
- but, 성능이 좋지 않으니 추가할 요소가 적으면 직접 lengh사용해서 추가해라
- 원본 배열 변경하므로 스프레드 문법을 사용해라
const arr = [1, 2];
// ES6 스프레드 문법
const newArr = [...arr, 3];
console.log(newArr); // [1, 2, 3]
Array.prototype.pop
원본 배열에서 마지막 요소 제거하고 반환.
비어있으면 undefined 반환
const arr = [1, 2];
// 원본 배열에서 마지막 요소를 제거하고 제거한 요소를 반환한다.
let result = arr.pop();
console.log(result); // 2
// pop 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [1]
그외 Array 내장 메서드
Array.isArray: 인수가 배열이면 true 아니면 falseArray.prototype.pop: 원본 배열에서 마지막요소 제거하고 제거한 요소 반환Array.prototype.unshift: 전달받은 모든값을 선두에 요소로 추가. lenght 반환Array.prototype.shift: 첫번째 요소 제거하고 반환.Array.prototype.concat: 인수 추가해서 새로운 배열 반환`
배열 고차 함수
Array.prototype.sort
배열의 요소를 정렬한다. 원본배열을 직접 변경하고 정렬된 배열을 반환한다.
문자열은 잘 정렬하는데, 숫자로 이루어진 배열 정렬할 때 주의 해야함.
const points = [40, 100, 1, 5, 2, 25, 10];
points.sort();
// 숫자 요소들로 이루어진 배열은 의도한 대로 정렬되지 않는다.
console.log(points); // [1, 10, 100, 2, 25, 40, 5]
정렬 순서를 정의하는 비교함수를 인수로 전달해야함.
const points = [40, 100, 1, 5, 2, 25, 10];
// 숫자 배열의 오름차순 정렬. 비교 함수의 반환값이 0보다 작으면 a를 우선하여 정렬한다.
points.sort((a, b) => a - b);
console.log(points); // [1, 2, 5, 10, 25, 40, 100]
// 숫자 배열에서 최소/최대값 취득
console.log(points[0], points[points.length]); // 1
// 숫자 배열의 내림차순 정렬. 비교 함수의 반환값이 0보다 작으면 b를 우선하여 정렬한다.
points.sort((a, b) => b - a);
console.log(points); // [100, 40, 25, 10, 5, 2, 1]
// 숫자 배열에서 최대값 취득
console.log(points[0]); // 100
객체 sort
const todos = [
{ id: 4, content: 'JavaScript' },
{ id: 1, content: 'HTML' },
{ id: 2, content: 'CSS' }
];
// 비교 함수. 매개변수 key는 프로퍼티 키다.
function compare(key) {
// 프로퍼티 값이 문자열인 경우 - 산술 연산으로 비교하면 NaN이 나오므로 비교 연산을 사용한다.
// 비교 함수는 양수/음수/0을 반환하면 되므로 - 산술 연산 대신 비교 연산을 사용할 수 있다.
return (a, b) => (a[key] > b[key] ? 1 : (a[key] < b[key] ? -1 : 0));
}
// id를 기준으로 오름차순 정렬
todos.sort(compare('id'));
console.log(todos);
/*
[
{ id: 1, content: 'HTML' },
{ id: 2, content: 'CSS' },
{ id: 4, content: 'JavaScript' }
]
*/
// content를 기준으로 오름차순 정렬
todos.sort(compare('content'));
console.log(todos);
/*
[
{ id: 2, content: 'CSS' },
{ id: 1, content: 'HTML' },
{ id: 4, content: 'JavaScript' }
]
*/
Array.prototype.forEach
forEach메서드는 내부에서 반복문을 통해 자신을 호출한 배열을 순회하면서 콜백 함수로 반복 호출한다.
forEach 메서드는 콜백함수를 호출할 때, 1. 배열의 요소값 2. 배열의 인덱스 **3. 호출한 배열(this)**를 전달한다.
// forEach 메서드는 콜백 함수를 호출하면서 3개(요소값, 인덱스, this)의 인수를 전달한다.
[1, 2, 3].forEach((item, index, arr) => {
console.log(`요소값: ${item}, 인덱스: ${index}, this: ${JSON.stringify(arr)}`);
});
/*
요소값: 1, 인덱스: 0, this: [1,2,3]
요소값: 2, 인덱스: 1, this: [1,2,3]
요소값: 3, 인덱스: 2, this: [1,2,3]
*/
forEach 메서드는 두번재 인자로 this를 전달할 수 있다. 사실 더 좋은 방법은 화살표 함수를 사용하는 것이다.
class Numbers {
numberArray = [];
multiply(arr) {
arr.forEach(function (item) {
this.numberArray.push(item * item);
}, this); // forEach 메서드의 콜백 함수 내부에서 this로 사용할 객체를 전달
}
}
const numbers = new Numbers();
numbers.multiply([1, 2, 3]);
console.log(numbers.numberArray); // [1, 4, 9]
희소 배열의 경우 존재 하지 않는 요소는 순회대상에서 제외된다. for과의 차이
for보다 성능이 좋지 않지만 가독성이 좋으니까 써라~
Array.prototype.map
배열의 모든 요소를 순회하면서 콜백함수를 호출. 콜백 함수의 반환값들로 구성된 새로운 배열을 반환
const numbers = [1, 4, 9];
// map 메서드는 numbers 배열의 모든 요소를 순회하면서 콜백 함수를 반복 호출한다.
// 그리고 콜백 함수의 반환값들로 구성된 새로운 배열을 반환한다.
const roots = numbers.map(item => Math.sqrt(item));
// 위 코드는 다음과 같다.
// const roots = numbers.map(Math.sqrt);
// map 메서드는 새로운 배열을 반환한다
console.log(roots); // [ 1, 2, 3 ]
// map 메서드는 원본 배열을 변경하지 않는다
console.log(numbers); // [ 1, 4, 9 ]
다른 특성들은 forEach와 비슷
Array.prototype.filter
배열의 모든 요소를 순회하면서 콜백함수를 호출. 콜백 함수의 반환값이 ture인 요소로만 구성된 새로운 새로운 배열을 반환
const numbers = [1, 2, 3, 4, 5];
// filter 메서드는 numbers 배열의 모든 요소를 순회하면서 콜백 함수를 반복 호출한다.
// 그리고 콜백 함수의 반환값이 true인 요소로만 구성된 새로운 배열을 반환한다.
// 다음의 경우 numbers 배열에서 홀수인 요소만을 필터링한다(1은 true로 평가된다).
const odds = numbers.filter(item => item % 2);
console.log(odds); // [1, 3, 5]
자신을 호출한 배열에서 특정 요소를 제거하기 위해 사용할 수도 있다.
class Users {
constructor() {
this.users = [
{ id: 1, name: 'Lee' },
{ id: 2, name: 'Kim' }
];
}
// 요소 추출
findById(id) {
// id가 일치하는 사용자만 반환한다.
return this.users.filter(user => user.id === id);
}
// 요소 제거
remove(id) {
// id가 일치하지 않는 사용자를 제거한다.
this.users = this.users.filter(user => user.id !== id);
}
}
const users = new Users();
let user = users.findById(1);
console.log(user); // [{ id: 1, name: 'Lee' }]
// id가 1인 사용자를 제거한다.
users.remove(1);
user = users.findById(1);
console.log(user); // []
Array.prototype.reduce
누산기
배열을 순회하면서 인수로 전달받은 콜백함수를 반복 호출한다.
각 콜백함수의 반환값을 다음 순회시에 전달하면서 결과를 쌓아간다.
- 콜백함수(누산값, 현재값, index, 배열)
- 초기값
을 인자로 받는다.
// [1, 2, 3, 4]의 모든 요소의 누적을 구한다.
const sum = [1, 2, 3, 4].reduce((accumulator, currentValue, index, array) => accumulator + currentValue, 0);
console.log(sum); // 10
위 코드의 작동과정은 다음과 같다.
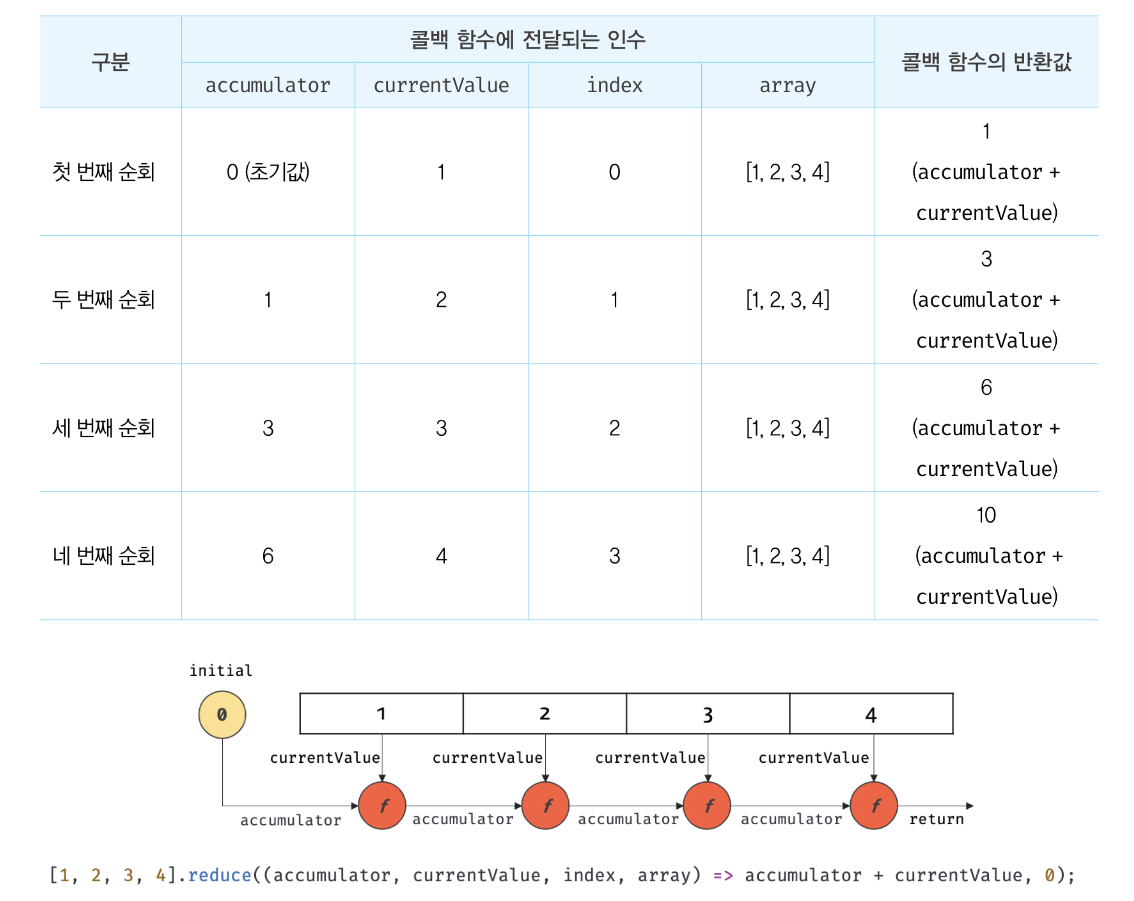
다른 순회 메서드들을 사용해서 할 수도 있지만, 한줄로 간단하게 사용할 수 있다.
Array.prototype.some
배열 요소 순회하면서 콜백함수 호출. return 값이 한번이라도 참이면 true, 모두 거짓이면 false반환.
빈배열 일 경우 flase 반환
// 배열의 요소 중에 10보다 큰 요소가 1개 이상 존재하는지 확인
[5, 10, 15].some(item => item > 10); // -> true
// 배열의 요소 중에 0보다 작은 요소가 1개 이상 존재하는지 확인
[5, 10, 15].some(item => item < 0); // -> false
// 배열의 요소 중에 'banana'가 1개 이상 존재하는지 확인
['apple', 'banana', 'mango'].some(item => item === 'banana'); // -> true
// some 메서드를 호출한 배열이 빈 배열인 경우 언제나 false를 반환한다.
[].some(item => item > 3); // -> false
Array.prototype.every
배열 요소 순회하면서 콜백함수 호출, return 값이 모두 참이면 true, 한 번이라도 거짓이면 false 반환.
빈 배열 일 경우 true 반환.
// 배열의 모든 요소가 3보다 큰지 확인
[5, 10, 15].every(item => item > 3); // -> true
// 배열의 모든 요소가 10보다 큰지 확인
[5, 10, 15].every(item => item > 10); // -> false
// every 메서드를 호출한 배열이 빈 배열인 경우 언제나 true를 반환한다.
[].every(item => item > 3); // -> true
Array.prototype.find
배요 요소 순회하면서 콜백함수 호출, return 값이 ture인 첫 번째 요소 반환.
const users = [
{ id: 1, name: 'Lee' },
{ id: 2, name: 'Kim' },
{ id: 2, name: 'Choi' },
{ id: 3, name: 'Park' }
];
// id가 2인 첫 번째 요소를 반환한다. find 메서드는 배열이 아니라 요소를 반환한다.
users.find(user => user.id === 2); // -> {id: 2, name: 'Kim'}
Array.prototype.findIndex
find의 인덱스 버전. 인덱스 반환함
const users = [
{ id: 1, name: 'Lee' },
{ id: 2, name: 'Kim' },
{ id: 2, name: 'Choi' },
{ id: 3, name: 'Park' }
];
// id가 2인 요소의 인덱스를 구한다.
users.findIndex(user => user.id === 2); // -> 1
// name이 'Park'인 요소의 인덱스를 구한다.
users.findIndex(user => user.name === 'Park'); // -> 3
// 위와 같이 프로퍼티 키와 프로퍼티 값으로 요소의 인덱스를 구하는 경우
// 다음과 같이 콜백 함수를 추상화할 수 있다.
function predicate(key, value) {
// key와 value를 기억하는 클로저를 반환
return item => item[key] === value;
}
// id가 2인 요소의 인덱스를 구한다.
users.findIndex(predicate('id', 2)); // -> 1
// name이 'Park'인 요소의 인덱스를 구한다.
users.findIndex(predicate('name', 'Park')); // -> 3
Array.prototype.flatMap
배열을 평탄화 한다.
즉, map 메서드와 flat 메서드를 순차적으로 실행하는 효과
const arr = ['hello', 'world'];
// map과 flat을 순차적으로 실행
arr.map(x => x.split('')).flat();
// -> ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
// flatMap은 map을 통해 생성된 새로운 배열을 평탄화한다.
arr.flatMap(x => x.split(''));
// -> ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
단 평탄화 깊이를 지정할 수는 없다.
const arr = ['hello', 'world'];
// flatMap은 1단계만 평탄화한다.
arr.flatMap((str, index) => [index, [str, str.length]]);
// -> [[0, ['hello', 5]], [1, ['world', 5]]] => [0, ['hello', 5], 1, ['world', 5]]
// 평탄화 깊이를 지정해야 하면 flatMap 메서드를 사용하지 말고 map 메서드와 flat 메서드를 각각 호출한다.
arr.map((str, index) => [index, [str, str.length]]).flat(2);
// -> [[0, ['hello', 5]], [1, ['world', 5]]] => [0, 'hello', 5, 1, 'world', 5]